动动手做一个UserAgent库

作为一个爬虫脚本,基本的伪装是很必要的。而User-Agent头这个看似不起眼的元素,却起着至关重要的作用。
当然,这里还是需要科普下UA,是何物。
什么是UA
Wiki:在计算机科学中,用户代理(英语:User Agent)指的是代表用户行为的软件代理程序所提供的对自己的一个标识符。
我:简而言之就是访问者的身份证。
发现之旅
那么在常规爬虫脚本的编写中,通过每次请求虚假的UA来装饰每次请求,同样能达到一定的伪装作用,较为直观的理解就是,例如戴了个口罩。

废话不多说,说干就干,首先我们打开谷歌(不要问我是怎么打开的。。)并输入user agent list,回车。
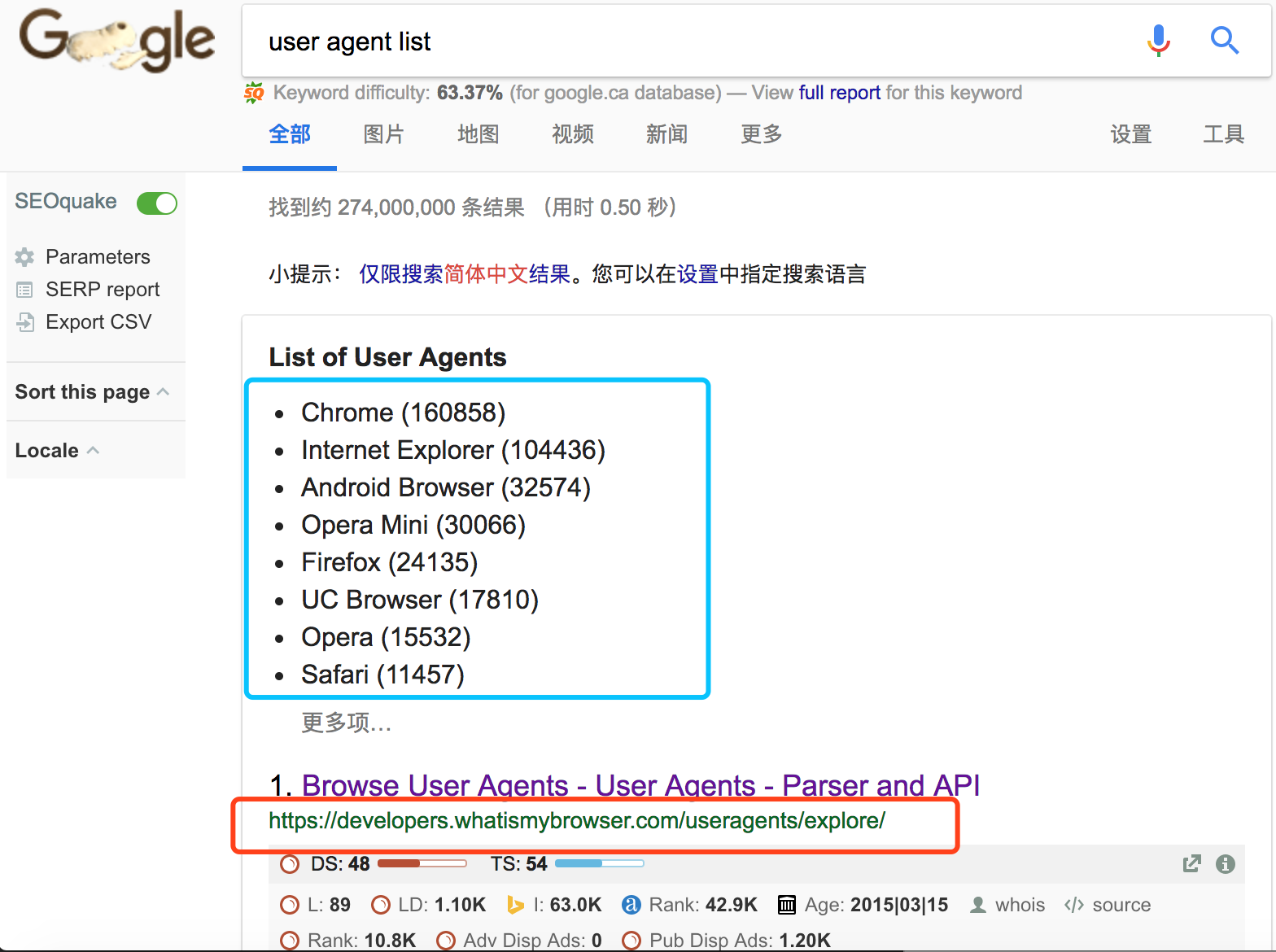
这个时候我们可以看到结果中蓝框内有着令人兴奋的结果,UA的基础分类。 而红框内为此结果的源URL地址。于是我们访问这个站点。
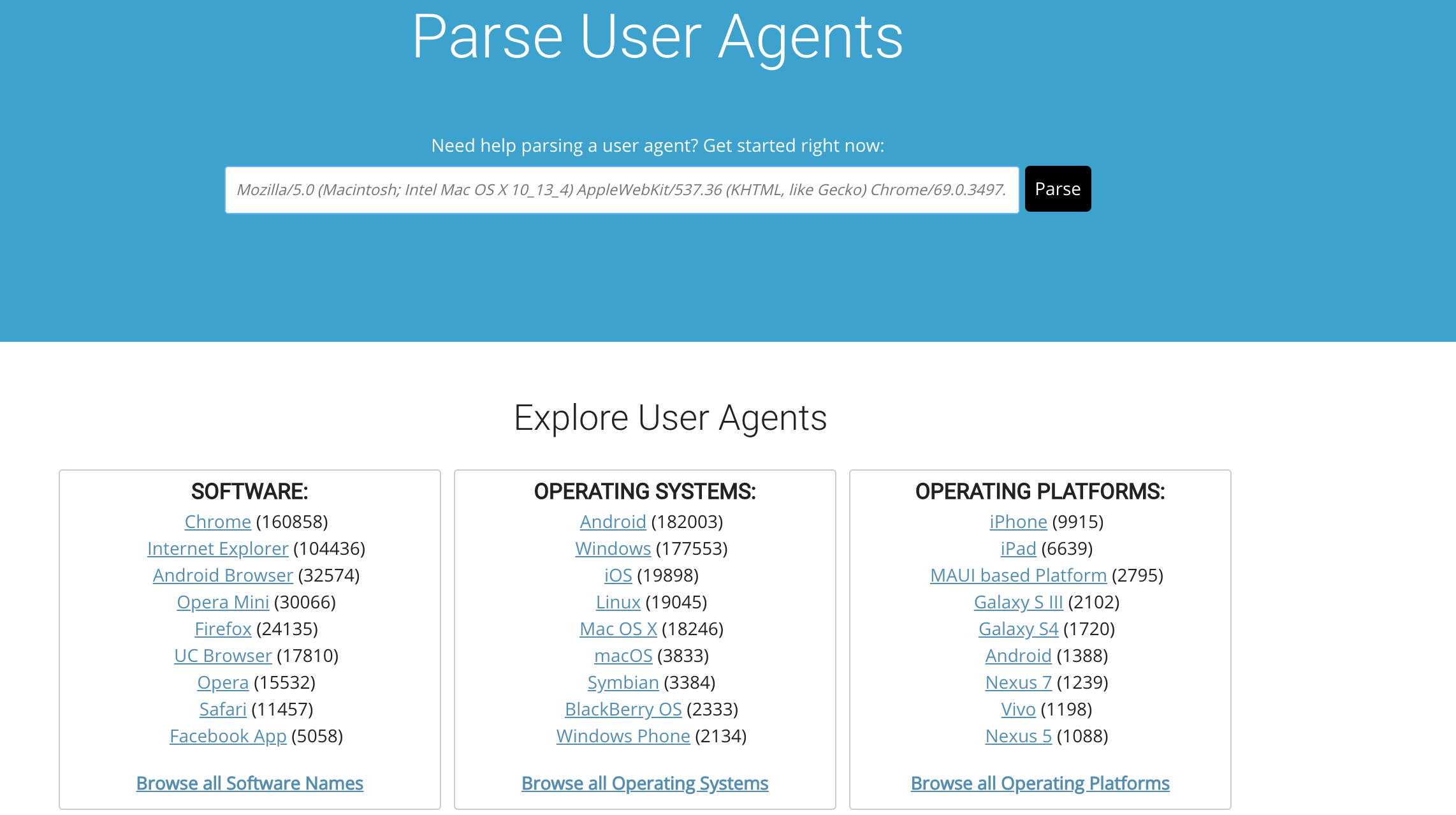
我们可以看到列表通过用途进行了一定分类。于是我们进行了一定的对比分析。
https://developers.whatismybrowser.com/useragents/explore/software_name/chrome/
https://developers.whatismybrowser.com/useragents/explore/software_name/internet-explorer/
https://developers.whatismybrowser.com/useragents/explore/operating_system_name/windows/
https://developers.whatismybrowser.com/useragents/explore/operating_platform/nexus-5/
不难看出,这个站点根据尾部的两级目录进行了分类
\type1\
\type2\
\page
说得直白一点,这或许是 三个循环 就能搞定的事情,当然page得根据抓取结果来判定。
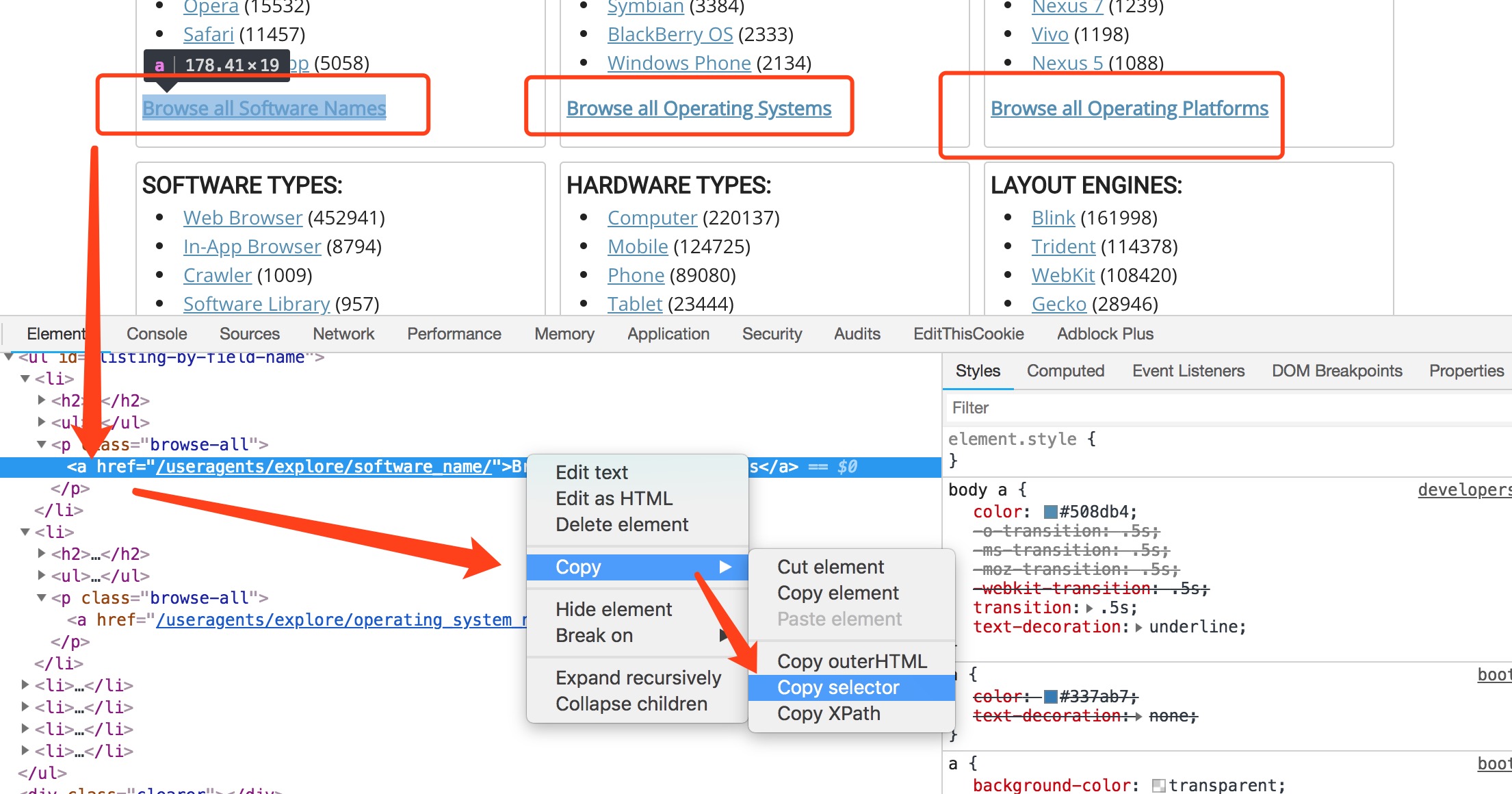
首先我们需要获取到全部的分类链接,也就是上 图中第一个箭头指向元素的 href属性,这里我们通过chrome调试工具直接选取到红框元素css路径并进行对比总结出通用路径
# listing-by-field-name > li:nth-child(1) > h2 > a
# listing-by-field-name > li:nth-child(2) > h2 > a
# listing-by-field-name > li > h2 > a
并且我们可以发现,下级目录直接给出了二级类型及其总数量,具体取法同上文不再赘述。
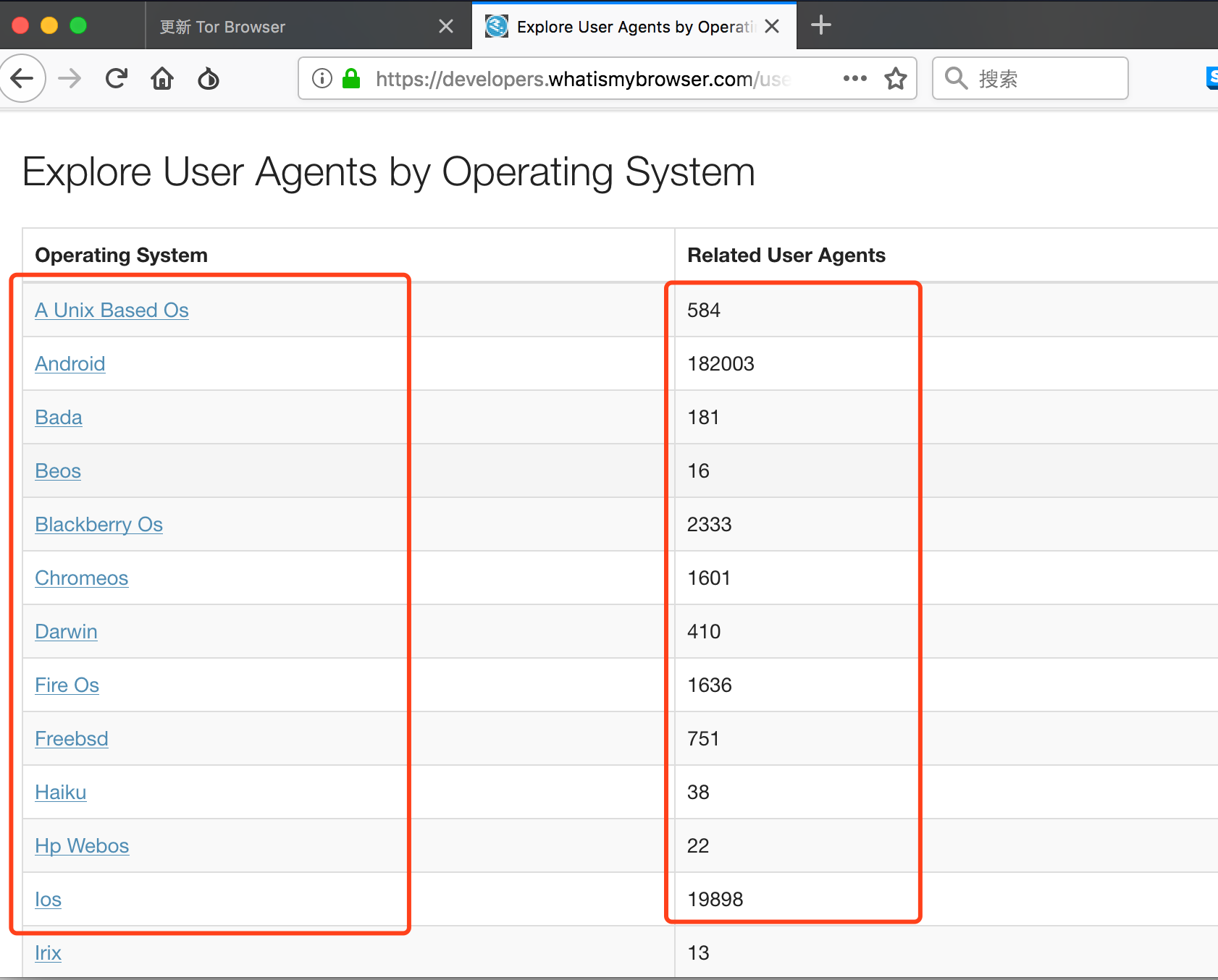
我们通过访问任意类型的任一一页,并统计单页数量来直接计算出总页数。那么怎么快速计算呢。这里我们来观察下数据集所处的dom位置。
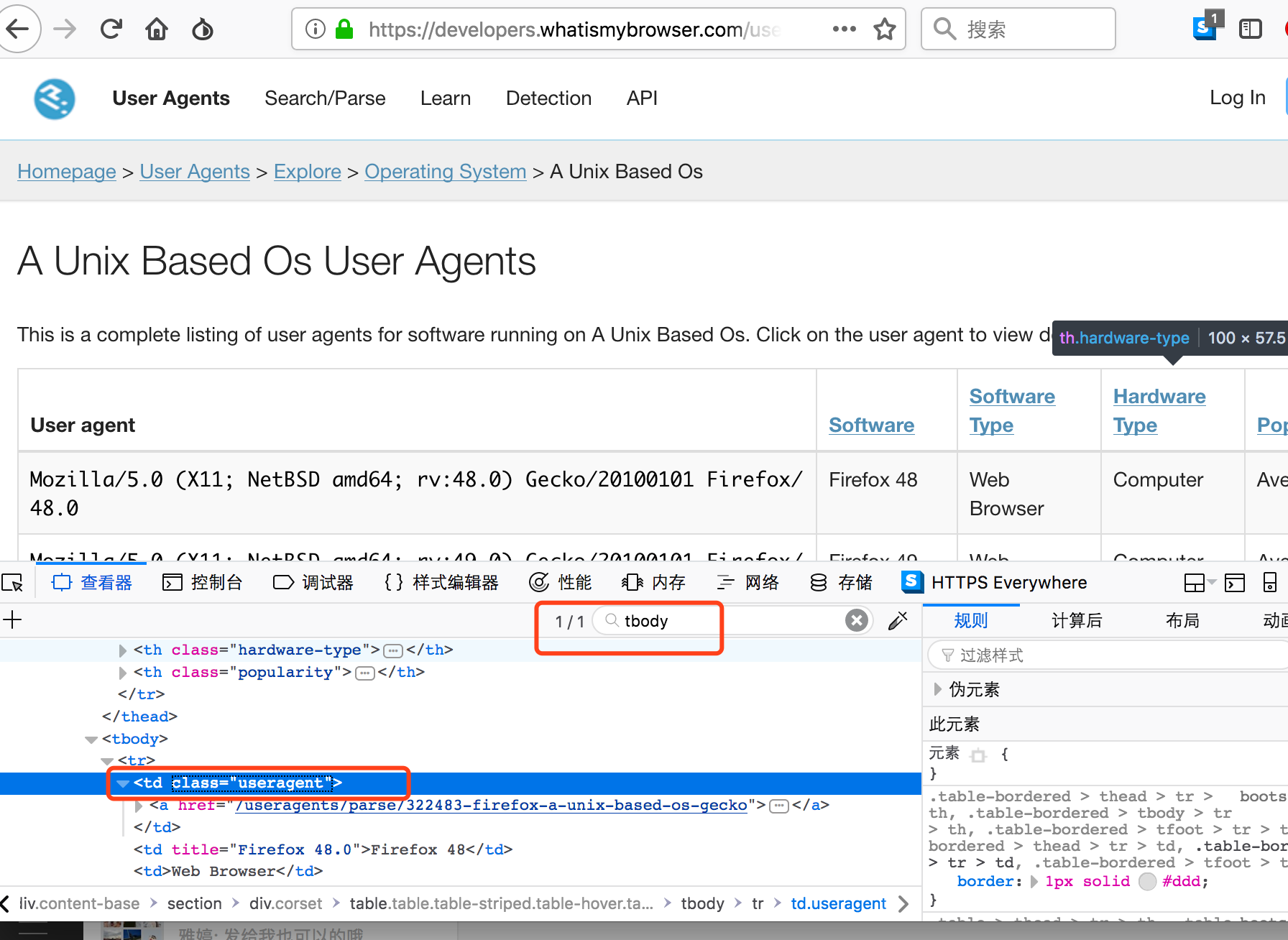
可以看到全文就一个tbody标签,并且每项的一个td标签存在useragent这样一个类属性。如此就好办了。我们可以通过编写js语句来直接读取单页总数。
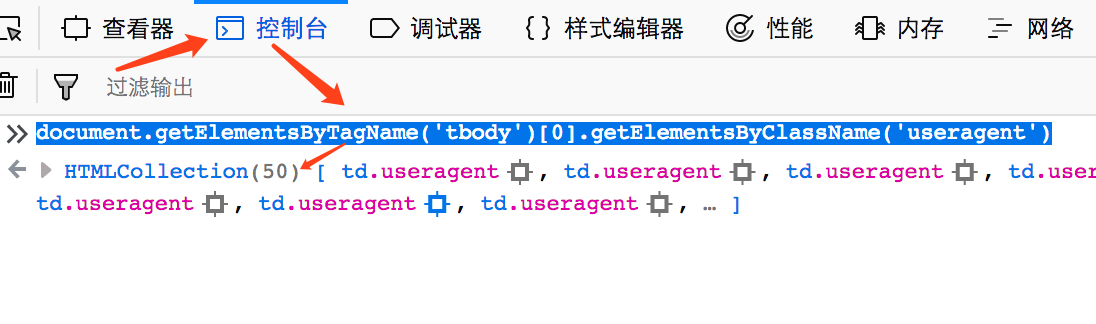
于是总页数就为math.ceil(nums/50)
如此一来,一二级目录名称及总页数都找到了解决办法,这个时候我们就可以开始coding了。在编写过程中,我们发现这个站点也是对访问频率进行了一定限制,而Tor代理可以很好地绕过。具体手法详见【url】。
考虑到我们使用的异步模块asks并没有proxy配置项,于是经过一番搜寻,我们找到了一个很好的命令行代理,接下来我给大家介绍它及其使用方法。
命令代理ProxyChain4(以MAC为例)
使用环境
Linux, BSD, MAC(win用户的悲剧)
软件安装
这里我们通过brew来管理软件包,具体关于brew的安装方式不再赘述。
brew install proxychains-ng
软件配置
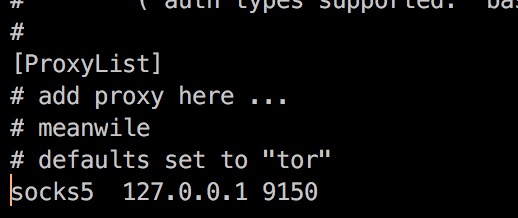
我们通过vim编辑配置文件vi /usr/local/etc/proxychains.conf,搜索[ProxyList](一般在底部) 在其下方加上 socks5 127.0.0.1 9150(此为Tor代理节点)并保存。
使用方法
这个神奇的插件可以通过proxychains4 [你要运行的命令] 来让任何命令经过代理

当然它还能这样,如下是一张鲜明的对比图。
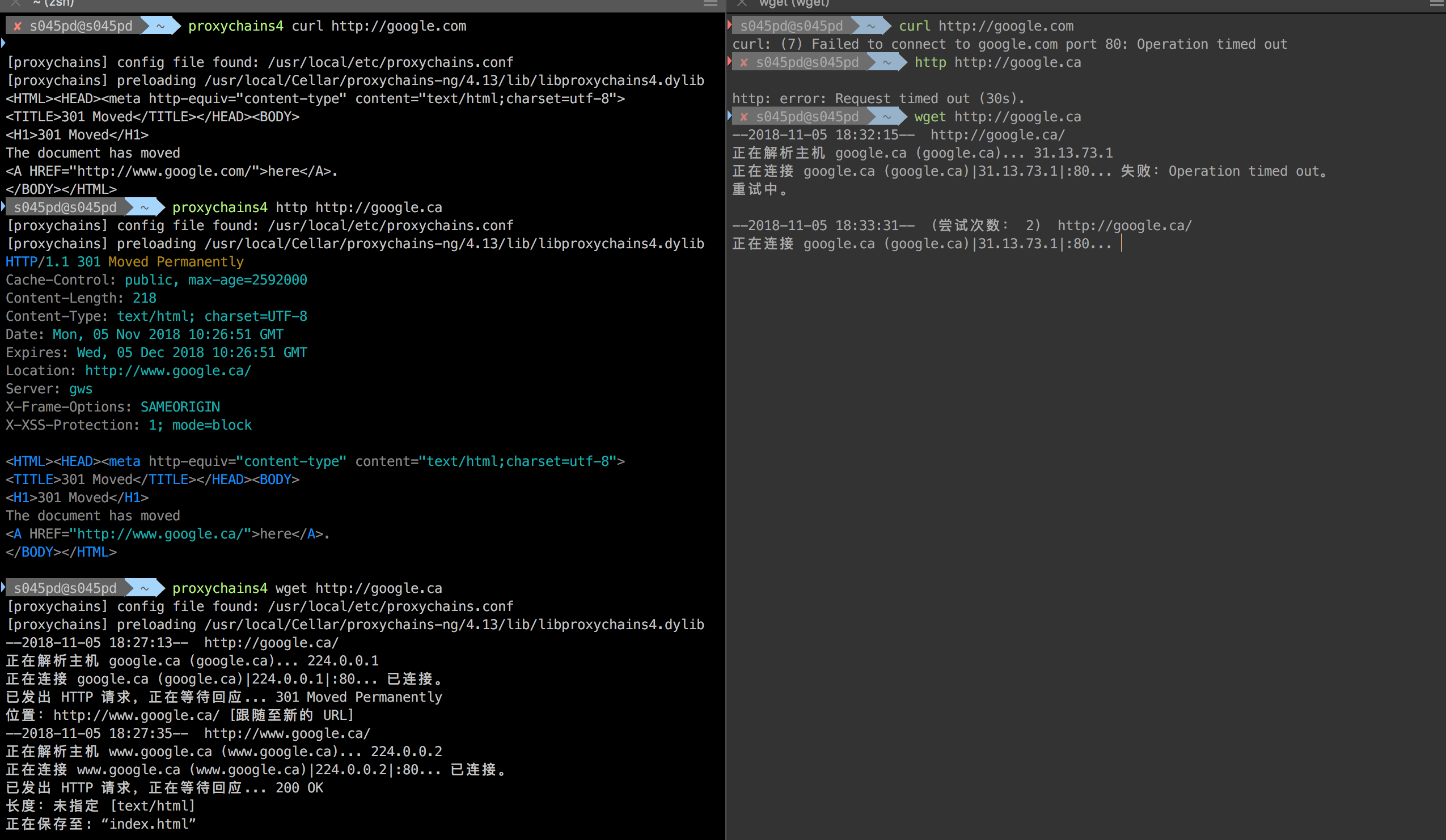
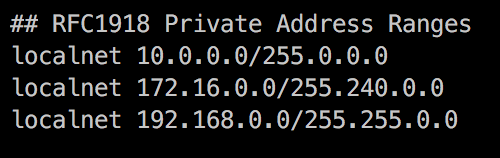
想必也有人会问,是否本地地址也会走代理,答案是,默认是的。需要通过修改配置才能跳过本地地址,找到如下配置并去掉**#**号即可。
数据存储
为了快速构建我们选择使用sqlite,并通过模块peewee来构建ORM,没有安装的同学可以通过pip install peewee来安装。
首先我们来配置表字段
from peewee import *
db = SqliteDatabase('useragents.db') # 初始化数据库
class UAS(Model):
uid = AutoField(primary_key=True, null=True) # 自增ID
useragent = TextField() # UA
software = CharField(null=True) # 软件类型
engine = CharField(null=True) # 引擎
types = CharField(null=True) # 硬件类型
popularity = CharField(null=True) # 通用性
class Meta:
database = db # 指定数据库
db.connect() # 连接数据库
db.create_tables([UAS]) # 初始化创建不存在的库
这样我们就完成了表配置,考虑到脚本是异步执行,用同步代码会引发性能问题
,所以接下来我们需要在运行完之后再将数据存储。并且在编写中遇到一个问题。peewee的insert__many方法并不能一下子插入较多的数据,所以得将结果数据分块存储。
def MakeChunk(datas,length=100):
for item in range(1, math.ceil(len(datas)/length)):
yield datas[item*length:(item+1)*length]
在如上部分完成后,大致代码也已完成,这里截取爬了一定数量后中断的截图
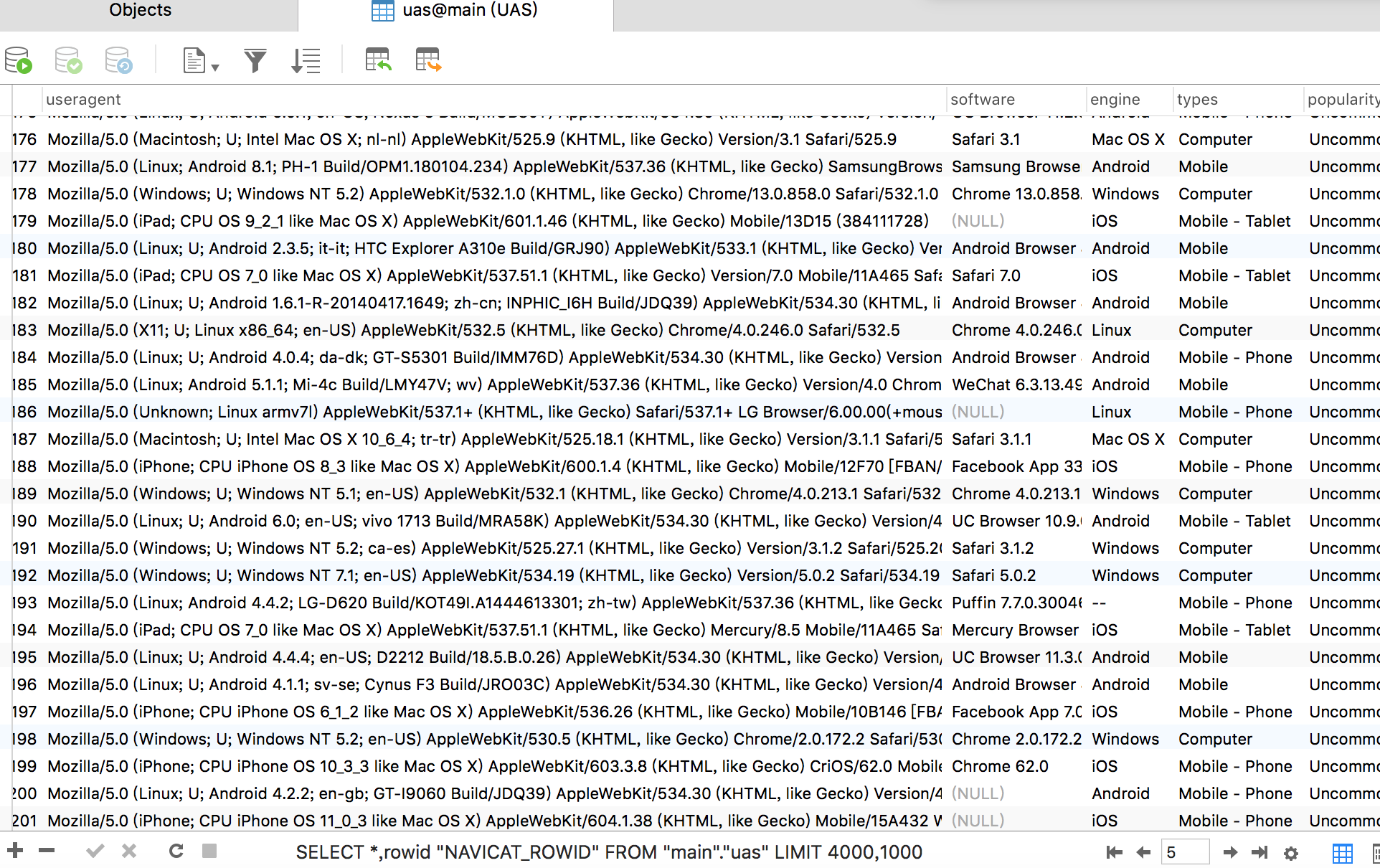
可以看到数据已经成功录入到了sqlite中
接下来就可以制作模块了。
查询代码
原本考虑使用Django来做但那样实用性是在太差于是就觉得做了个针对特定需求内容的过滤查询并随机取值
不多废话,直接上代码,这里我通过搜索关键内容searchwords字典传入希望查询的参数,当然这里并未支持模糊查询,这是有待改进的地方。并以methods为条件组合方法(与、或)进行查询。
def UserAgent(searchwords, methods='and'):
"""
searchwords:
{
"key":[
"words1",
"words2"
]
}
"""
count = 0
resagent = ''
if methods not in ['and', 'or']:
return ''
methods = '&' if not methods == 'or' else '|'
whereQuery = f' {methods} '.join([
f'(UAS.{key} << {str(item)})' for key, item in searchwords.items()
])
try:
count = UAS.select().where(eval(whereQuery)).order_by(fn.Random()).count()
resagent = UAS.select().where(eval(whereQuery)).order_by(
fn.Random()).limit(1)[0].useragent
except Exception as e:
pass
return count, resagent
结果将返回所能查询到的数据量及随机一个**UA**结果字段组成的元祖,当然如果查询出错也会以友好的方式返回
在这里我们使用如下案例测试一下
print(UserAgent({
"software": [
'Android Browser 4.0'
]
}))
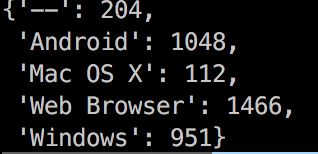
可以看到结果如下
不过可能会有同学问到,我要怎么知道其中包含哪些种类呢,自己写group by吗???
答案是当然不会,这里我们编写了一个UserAgentGroups(colname, limit=10)方法供开发者查阅,只需传入一个**类型字段colname及返回最大数量limit**即可。
例如:UserAgentGroups('engine', 5),返回结果如下图所示列表。