Webot微信机器人项目实战【通讯录导出与分析】

通过对上篇的阅读,我们已经学习到了对web微信的登录过程分析并成功进行模拟。那今天我们就接着讲,如何将个人通讯录列表导出为一个excel文件。
0x00 搜索思路
首先根据常规爬虫的方法,我们会从通讯录栏目开始入手。通过浏览器的开发者工具审查单个好友的头像我们发现,头像所对应的实际地址中有一段关键的get参即username=@9d22fd69c1e6f628da93ba5a06e4aaca成功得引起了我们的注意。
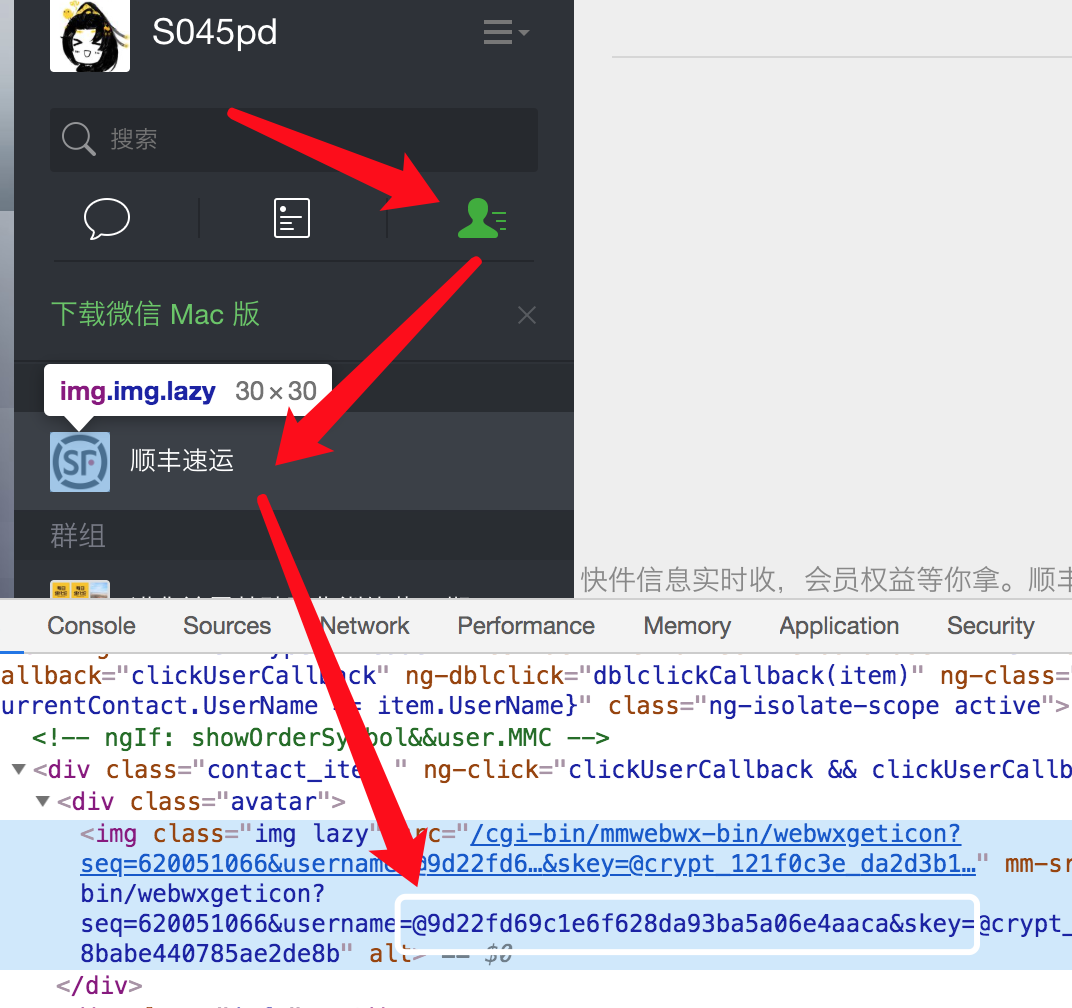
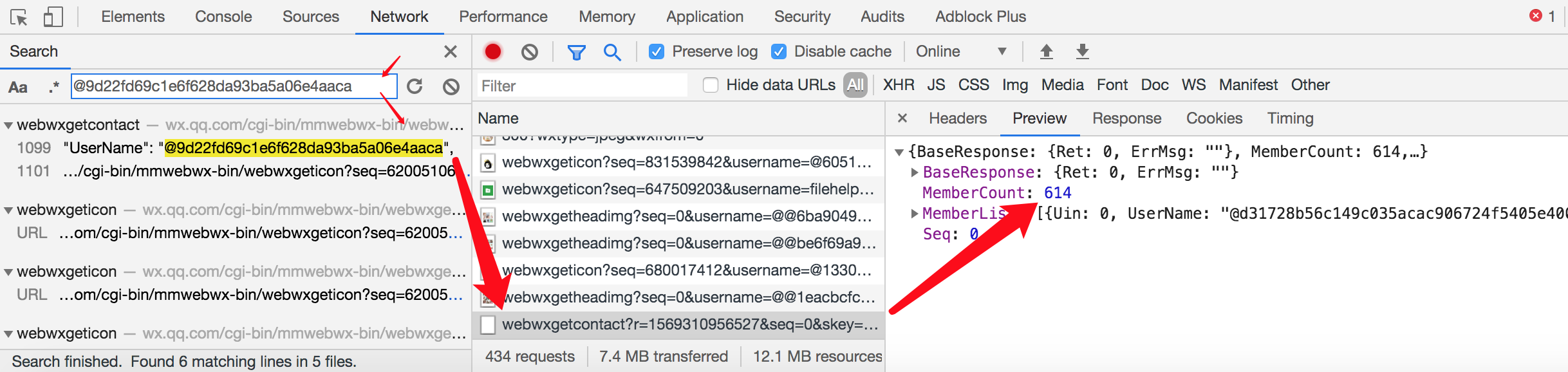
接下来我们通过在Network中进行过滤存在@9d22fd69c1e6f628da93ba5a06e4aaca的请求。成功得截取到几段请求,其中第一段路径结尾为webwxgetcontact且响应结果为一段标准json。
而MemberCount为个人的好友数量,MemberList为全部好友的摘要信息。非常好,现在我们已经成功得找到了获取通讯录概要的请求。
0x01 登录初始化补充
在上一篇文章里面我们成功登录,不过在我的大意之下漏掉了获取登录后的初始化信息过程,也就是对 webwxinit的模拟,在这里补上。
首先我们看到。该请求为一个POST请求,其中包含一个r键param及格式为{BaseRequest: {Uin: "918200740", Sid: "KucuigStPnvhKEz1", Skey: "", DeviceID: "e054282334933604"}}的请求体。通过关键webwxinit搜索,我们发现了该请求的实际组成。
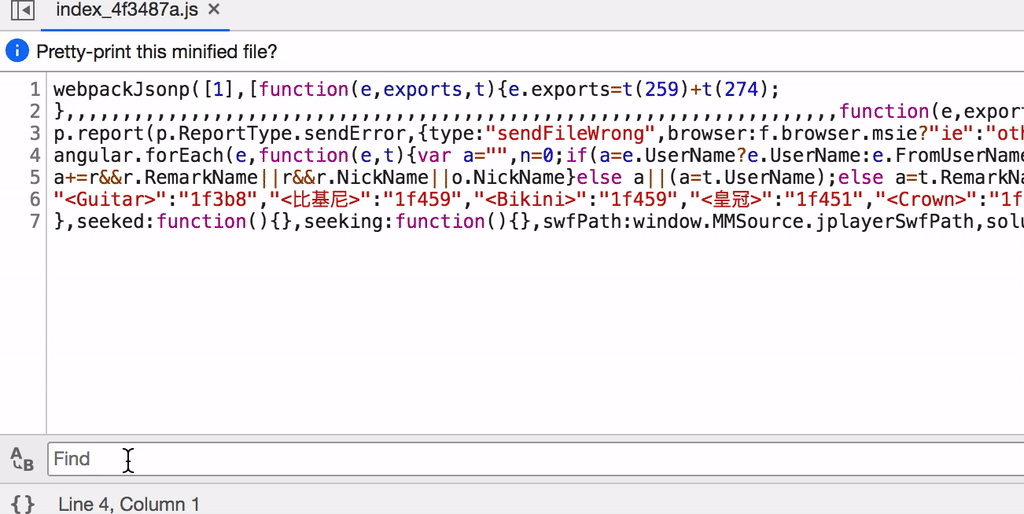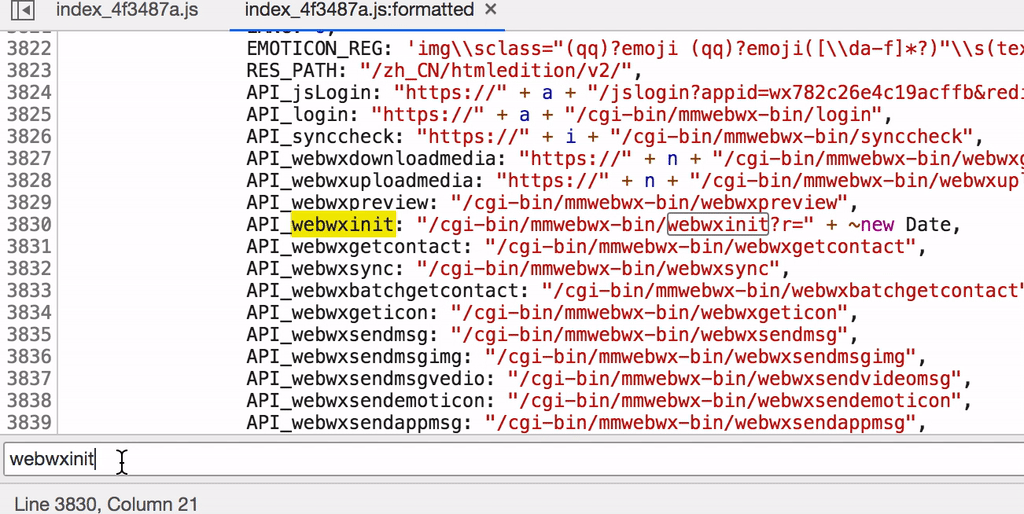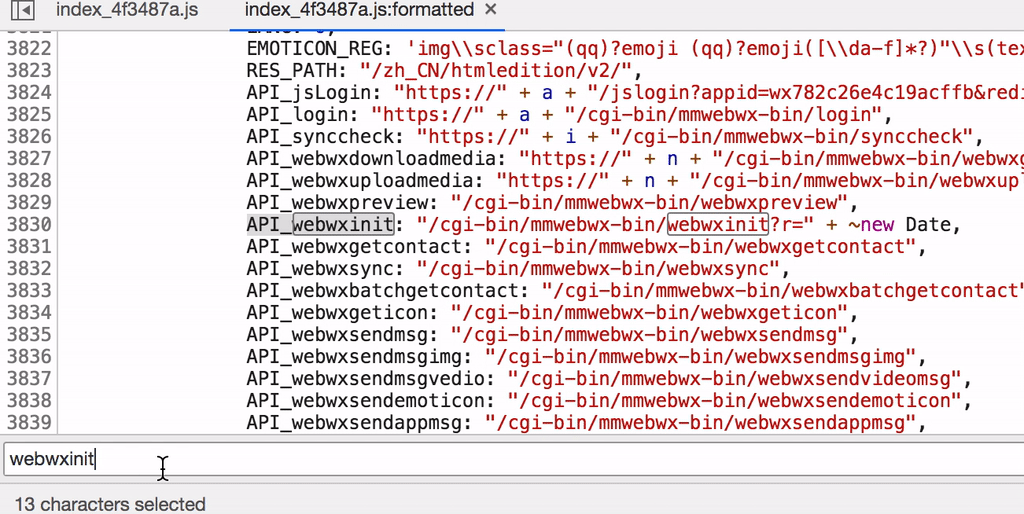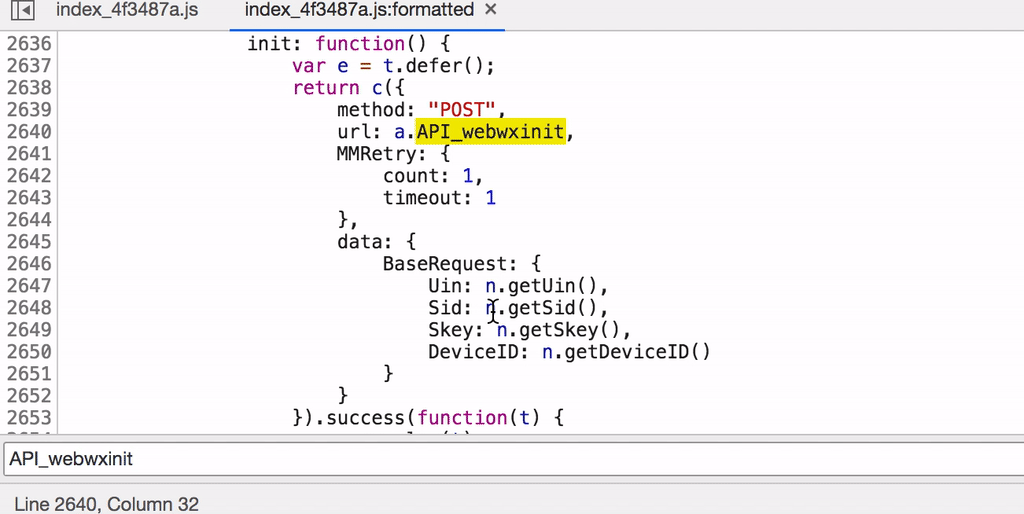
并且经过进一步搜索我们获取了Uin、Sid、Skey、DeviceID四项的获取方式,前三者均从auth_data中获取,而DeviceID为固定生成的随机数据。接下来我们编写脚本模拟登录后初始化。
# 承接上文所有import、方法及数据
mport random
API_webwxinit = "https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxinit"
my_id = ""
def create_device_id():
return f"e{str(random.random())[2:17]}"
def get_base_request():
return {
"BaseRequest": {
"Uin": auth_data["wxuin"],
"Sid": auth_data["wxsid"],
"Skey": auth_data["skey"],
"DeviceID": create_device_id(),
}
}
def login_success_init():
resp = session.post(
API_webwxinit, params={"r": get_timestamp(True)}, json=get_base_request()
)
resp.encoding = "utf8"
data = resp.json()
my_id = data["User"]["UserName"]
print(f"{'Welcome'.center(20,'*')}: [{data['User']['NickName']}]")
return data
person_data = login_success_init()
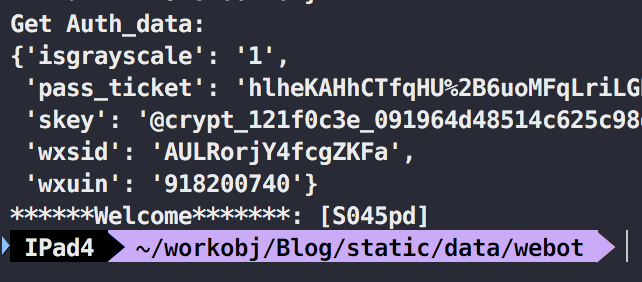
接下来,我们运行脚本。可以看到我的昵称S045pd成功得打印在了屏幕上。
0x02 获取通讯录详情
在完成登录初始化之后,我们开始编写获取通讯的代码。首先我们查看该请求附带了4个参数且都可以在在现有数据中获取到,例如skey就包含在auth_data中。

我们将其转变为如下代码。并将获取到的好友数量进行打印,整个结果赋值给contacts
# 承接上文所有import、方法及数据
API_webwxgetcontact = "https://wx.qq.com/cgi-bin/mmwebwx-bin/webwxgetcontact"
contacts = {}
def get_contact():
resp = session.get(
API_webwxgetcontact,
params={
"lang": "zh_CN",
"r": get_timestamp(),
"seq": 0,
"skey": auth_data["skey"],
},
)
data = resp.json()
print(f"Get friends: [{data['MemberCount']}]")
return data
contacts = get_contact()
获取到了616个好友,比前几十分钟前多了俩。

我们将结果存入了contacts变量中以作备用。这边随机选取了一段内容 可以看到其中有很多字段可以直接根据键名知道大概的意思。
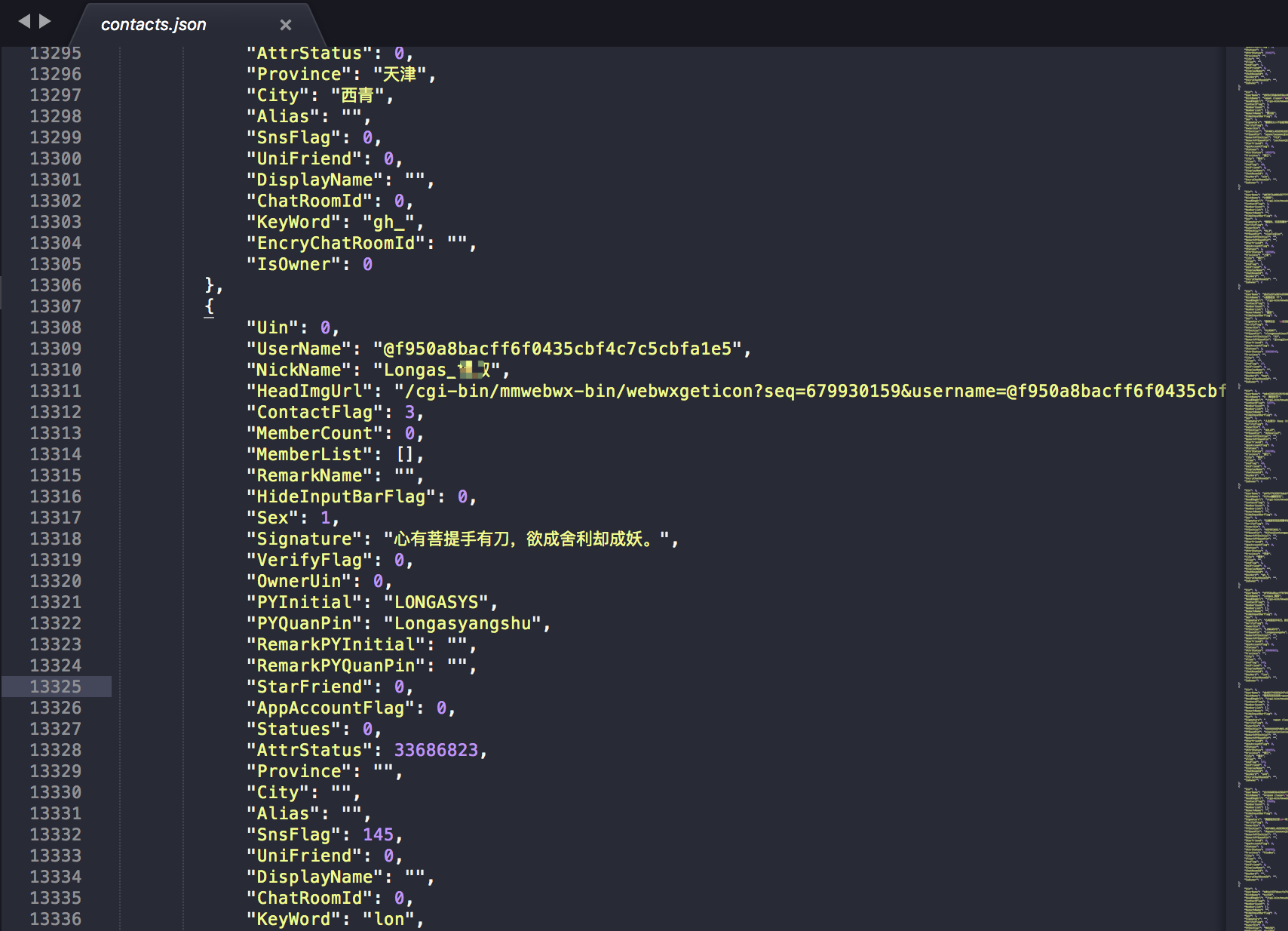
例如:
Signature个性签名Sex性别NickName昵称Province所在省
…等等我就不一一列举了
0x03 数据导出
contacts以字典的方式保存着个人通讯录的数据,而现在就到了将它转换成一个excel的时候了。为了不让结果内容更直观,我们决定将每个人的头像一并获取到。
首先我们设定好主域名链接MAIN_URI及媒体文件存放目录对象MEDIA_PATH备用。
# 承接上文所有import、方法及数据
import progressbar
import string
import pathlib
from io import BytesIO
from openpyxl import Workbook
from openpyxl.drawing.image import Image as openpyxlImage
from PIL import Image
from urllib.parse import urljoin
MAIN_URI = "https://wx.qq.com/"
MEDIA_PATH = pathlib.Path("images")
继而通过预设一个get_pic作为头像抓取的方法。结果以用户昵称拼音缩写作为文件名存入images当中并返回图像二进制内容。
def get_pic(data):
try:
img = session.get(urljoin(MAIN_URI, data["HeadImgUrl"])).content
with (MEDIA_PATH / f"{data['PYInitial']}_{data['VerifyFlag']}.png").open("wb") as file:
file.write(img)
return img
except Exception as e:
print(e)
最后我们编写了export_all_contact作为生成并导出为excel文件的方法。由于要插入图片,所以我们选用了openpyxl而不是常见的pandas。
def export_all_contact():
wb = Workbook()
sheet = wb.active
keys = contacts["MemberList"][0].keys()
for x, key in enumerate(keys): # 将列名写入第一行
sheet.cell(row=1, column=x + 1, value=key)
# 逐行写入数据
for y, item in progressbar.progressbar(enumerate(contacts["MemberList"])):
y = y + 2
for x, key in enumerate(keys): # 每行逐列写入数据
x = x + 1
value = item[key] # 待填充值
if key != "HeadImgUrl": # 判断是否不为图片路径字段
if key == "MemberList":
value = "".join(value)
sheet.cell(row=y, column=x, value=value) # 常规插入
else:
# 如果是图片路径那么就取到图片二进制流
pic = get_pic(item)
if pic: # 确认确实有内容
x = x - 1
index_code = string.ascii_uppercase[x] # 获取到对应列的字母
size = (50, 50) # 指定图片的大小
sheet.column_dimensions[index_code].width, sheet.row_dimensions[
y
].height = size # 指定将单元格长宽
img = openpyxlImage(BytesIO(pic)) # 转换为行内可用图像
img.width, img.height = size # 指定图像大小
sheet.add_image(img, f"{index_code}{y}") # 插入该图
else:
sheet.cell(row=y, column=x, value="") # 没有图就空着
wb.save("contacts.xlsx")
运行前我们先判断下媒体目录是否存在,如果不存在就创建,然后再运行导出程序。
if not MEDIA_PATH.exists():
MEDIA_PATH.mkdir()
export_all_contact()
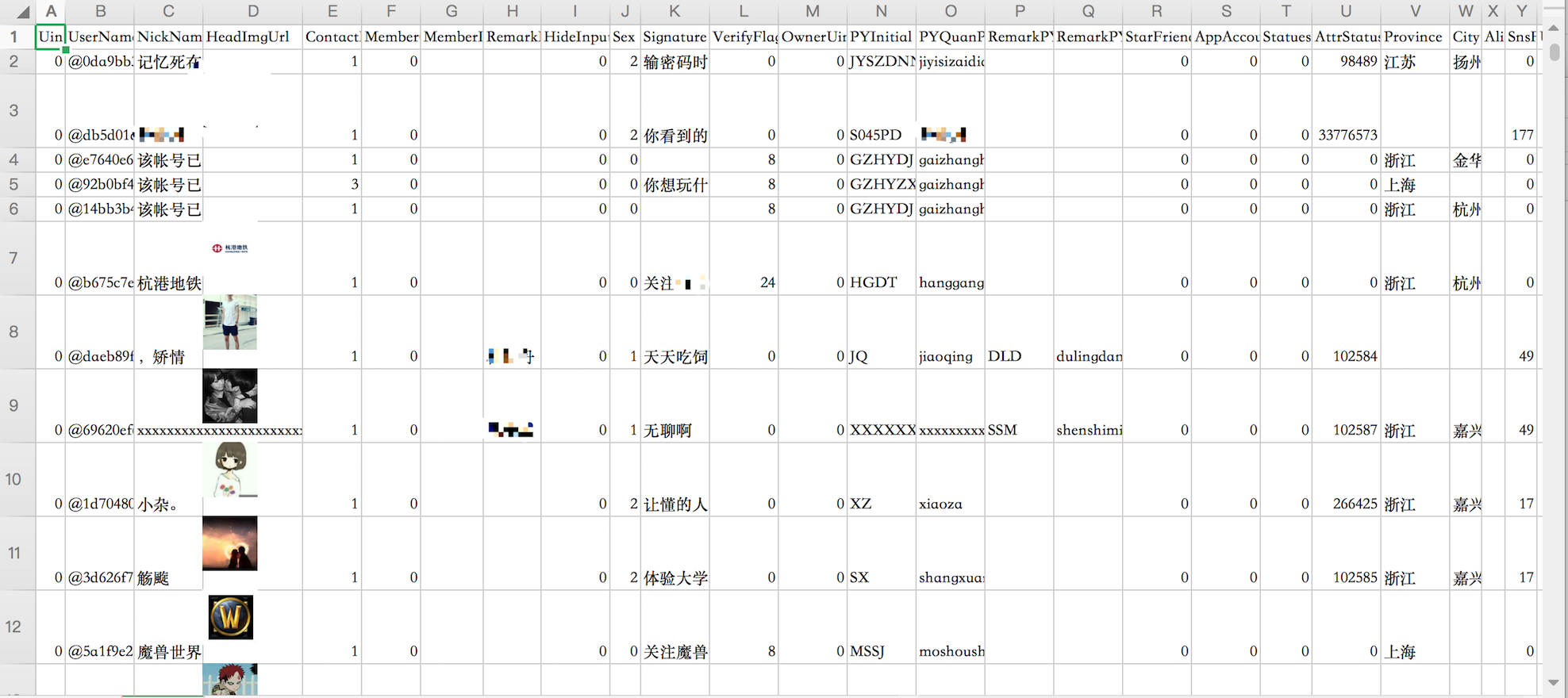
可以看到每个人的数据被不断的读取并获取头像,最终生成了contacts.xlsx文件

现在我们打开该文件,结果就像下图。
0x04 数据分析
1. 好友城市分布
我们将使用pyechart模块作为基础并以旭日图的方式来展现好友地区分布关系。这边我们将把数据转移至jupter-notebook做更好得展现。
首先我们引入必备的模块,并设定一个random_color作为旭日图单块区域的随机色以增强对比。
# 承接上文所有import、方法及数据
from pyecharts import options as opts
from pyecharts.charts import Sunburst
def random_color(): # 随机颜色
return "#"+''.join([random.choice('0123456789abcdef') for j in range(6)])
继而我们需要吧contacts数据转换为如下格式,例如parent1为北京,child1为朝阳区。colorN则为随机色。
{
"name" : "[parent1]",
"itemStyle": {
"color": "[colorN]"
},
"children": [
{
"name": "[child1]",
"value": 1,
"itemStyle": {
"color": "[colorN]"
},
...
},
...
]
}
于是我们使用如下format_sunburst_city方法将其整理为所需格式。需要注意的是,web微信所给出的数据中有部分province较长的值,这边我们通过一个长度判断len(province)>5给过滤掉了。
def format_sunburst_city(data): # 整理好友城市数据,将其变为一个可以直接使用的字典
datas = {}
for item in data["MemberList"]:
province = item['Province']
city = item['City']
if len(province) >5:
continue
if province not in datas:
datas[province] = {}
if city not in datas[province]:
datas[province][city] = 1
else:
datas[province][city] += 1
result = []
for province,pitem in datas.items():
result.append({
'name': province,
'itemStyle': {
'color': random_color()
},
'children': [{
'name': city,
'value': citem,
'itemStyle': {
'color': random_color()
}
} for city,citem in pitem.items()]})
return result
contacts_formated = format_sunburst_city(contacts)
在成功整理好数据之后,我们通过sunburst_city将数据载入画布,生成交互式图像。
def sunburst_city(data) -> Sunburst: #直接带入固定格式数据生成图像
return (
Sunburst(init_opts=opts.InitOpts(width="1000px", height="600px")) # 设定画布长宽
.add(
"",
data_pair=data, # 载入数据
highlight_policy="ancestor",
radius=[0, "95%"],
sort_="null",
levels=[
{}, # 第一圈样式,如果有国家的话就不会空着
{
"r0": "15%",
"r": "45%",
"itemStyle": {"borderWidth": 2},
"label": {"rotate": "tangential"},
}, # 第二圈样式,对标省
{
"r0": "35%",
"r": "70%",
"label": {"position": "outside", "padding": 3, "silent": False},
"itemStyle": {"borderWidth": 1}
}, # 最外圈样式,对标市
],
)
.set_global_opts(title_opts=opts.TitleOpts(title="Sunburst-城市分布")) # 设定标题
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}")) #设定名称
)
sunburst_city(contacts_formated).render_notebook()
一切都进行得非常顺利,可以看到最多的果然是浙江的朋友。这边我们需要注意的是,如果我们并不是在jupter_notebook中处理,则需要将其替换为.reader()方法。

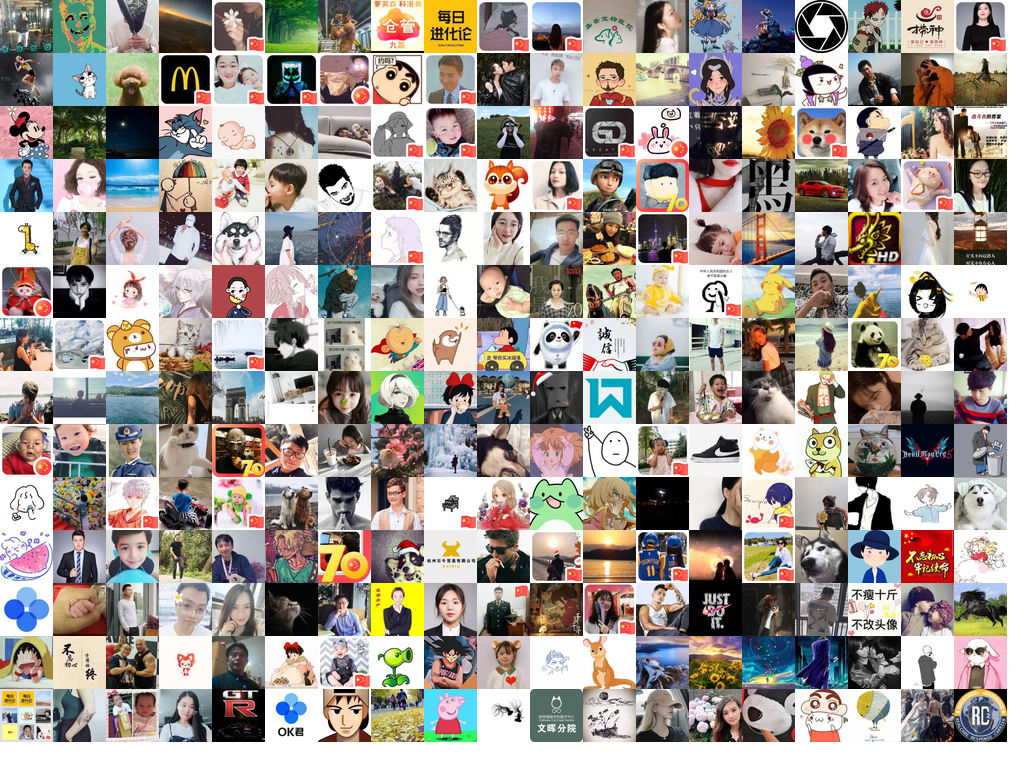
2. 头像图片墙制作
我们将所有的头像都存入了image文件夹中,现在就拿它们来搞点事情吧。制作一张精美的图片墙。
首先我们分析下图片墙的原理。
- 建立一张长为A 宽为B大小的图像作为画布,长宽比
16:9较为合适 - 获得抓取到的头像数量
- 通过面积计算每张头像需要被压缩到多少
- 将每张头像逐行填充到画布中,完成制作
我们设定画布大小为1024*768,并制定一个check_if_can_open作为检查png是否正常的方法。这边已经完成了第一个步骤。
from itertools import product
length, weight = (1024, 768)
def check_if_can_open(path):
try:
return Image.open(path)
except Exception as e:
pass
然后我们进行2、3、4步骤的操作,详见行间注释。
pathlib提供了一个很好的方法glob可以直接过滤出所需要的图片。
def make_friends_icon_wall():
images = list(filter(check_if_can_open, MEDIA_PATH.glob("*_0.png"))) # 搜索并过滤为个人的微信号
images_length = len(images) # 计算长度
per_size = int(math.sqrt(length * weight / images_length)) # 计算平均尺寸,正方形
image = Image.new("RGBA", (length, weight)) # 设定画布
for indexs, (x, y) in enumerate(product(range(int(length / per_size)), range(int(weight / per_size)))): # 迭代全部图像及XY坐标
if indexs >= images_length:
break
img = Image.open(images[indexs]) # 打开图像
img = img.resize((per_size, per_size), Image.ANTIALIAS) # 重新指定头像尺寸
image.paste(img, (x * per_size, y * per_size)) # 指定对应行列起始点,并粘贴头像
image.save("all.png") # 保存结果
make_friends_icon_wall()
现在我们得到了所有个人微信好友的图片墙,🤔好多国旗。。这里需要提一下,为什么我要使用*_0.png作为过滤规则。在先前存储头像的时候,我们特定得加上了其VerifyFlag字段,而这个字段就是对于微信号的属性。例如公众号、订阅号、个人、企业微信号等等。
3. 好友个性签名词云
在观察源数据的时候我们发现,较少部分的个签存在一些html代码,所以我们通过设定filter_html作为过滤方法。
import jieba
from wordcloud import WordCloud
from pyquery import PyQuery as jq
def filter_html(text):
try:
return jq(text).text()
except Exception as e:
return text
而后我们就开始生成词云,由于大部分签名都为中文会导致乱码,所以我们引入了中文字体库HYQiHei-25J.ttf来解决这个问题。
def make_friends_signature_word_cloud():
words = "\n".join([filter_html(item["Signature"]) for item in contacts["MemberList"]]) # 整合签名
jiebares = " ".join(jieba.cut(words)) # 中文分词
wc = WordCloud(
background_color="white",
font_path="HYQiHei-25J.ttf",
max_words=300,
max_font_size=40,
random_state=45,
) # 词云配置信息
wc.generate(jiebares) # 生成词云
wc.to_file("friends_signature_word_cloud.png") # 保存
make_friends_signature_word_cloud()
通过结果我们不难看出,但凡你生活活跃在上面圈子里头,身边的人就会和你有着类似的标签与共同的爱好。

下期将编写关于 《Webot微信机器人项目实战【消息的传送与接收】》。
在我的公众号后台回复:微信机器人导出与分析即可获得此次文章所用代码。
完整代码欢迎关注开源项目: Webot
更多精彩尽在公众号:进击的Hunter
![]()
