【项目实战】针对Twitter舆情进行LDA建模

2020年的开局确实比较悲惨,特别是在这几天,全球convid-19患者已超百万。那么现在。我们就通过推特抓取了350万条与virus相关的推文,看看墙外人民怎么看。
🍺本篇文章大约需要3分钟来阅读,届时你或许将学到:
-
如何善用强大的
Colab -
Twitter API流式过滤器的使用方法 -
部分数据清洗的方法
-
Normalization
-
Tokenization
-
Stop words
-
Lemmatization
-
-
快速生成
LDA主题模型的方法 -
在处理时我们该如何节约资源
首先我们来看看社交媒体对于病毒有着怎么样的描述
🤔嗯,长得真可怕。。

0x01 Colab改变生活

和以往的不同,为什么这次的任务推荐使用Colab呢。理由如下:
-
我们将使用到一个
Jupyter般的友好编写环境 -
它本身拥有国外的IP,抓取
Twitter数据会更省力 -
云端跑脚本可以节省你本地的计算及网络资源
-
可将抓取的数据实时存入
GoogleDrive -
它是免费的,并且可以额外安装其他库
0x02 Tweets的实时抓取
推特官方API本身提供实时推文的抓取接口,详见https://developer.twitter.com/en/docs/tutorials/consuming-streaming-data#consuming-the-stream ,具体细节不是本文的重点,不赘述。
所以我们将借助[tweepy](http://docs.tweepy.org/en/latest/index.html)项目来编写我们的抓取器。
1. 获取开发者账号
再者我们需要一个开发者账户,由于申请过程比较麻烦;且很多开发者喜欢把包含这类的内容传到Github,索引我们就去合理利用下。
2. 编写抓取器
通过上述过程拿到API账户后开始编写抓取器,首先我们需要经过认证方法。毕竟无用的账户是无法抓取到数据的
from tweepy import OAuthHandler
AUTH = OAuthHandler(API_KEY,API_SECRET)
AUTH.set_access_token(ACCESS_TOKEN,ACCESS_SECRET)
预设一个队列用于存储推文,我们给其设定了最大长度为1000w条,并且每获取1000条数据将追加保存open(file,'a')数据
最后实际抓了350w条 - - 太慢了。
from collections import deque
MAX_TWEETS = 1000*10000
CURRENT_TWEETS = 0
SAVE_NUMS = 1000
TWEETS = deque(maxlen=SAVE_NUMS)
预设一个进度条用于进度监控,就怕不耐心得你以为是程序卡住了。。
import progressbar
TWEETS_BAR = progressbar.ProgressBar(max_value=MAX_TWEETS)
3. 挂载GoogleDrive

我们使用如下代码来挂载,并设定了数据保存的位置datasets_path及推文文件tweets_file。这样一来你就不必担心数据没地方存啦
import pathlib
from google.colab import drive
root_google_path = pathlib.Path('/content/drive')
drive.mount(str(root_google_path), force_remount=True)
datasets_path = root_google_path / 'My Drive/Datasets'
if not datasets_path.exists():
datasets_path.mkdir()
tweets_file = datasets_path / f'Stream_tweets_virus_{MAX_TWEETS}.csv'
注意,期间在执行框中会出现要求输入认证口令。你只需要点击其链接,然后会认证你的账户并给出口令并粘贴到口令框即可。
3. 编写过滤规则
我们这里判断结束或者当前数量被整除的时候将进行保存。并且每次保存后情况TWEETS以节省有限的资源。并且我们将保存文字内容的repr,有人会问为啥呢?因为保存原本的text真的是太乱了。。
import json
from tweepy.streaming import StreamListener
class Monitor(StreamListener):
def on_data(self, data):
global CURRENT_TWEETS
if len(TWEETS) % SAVE_NUMS == 0 or CURRENT_TWEETS >= MAX_TWEETS:
pd.DataFrame(TWEETS).to_csv(
str(tweets_file),
mode="a",
index=False,
header=(not tweets_file.exists()),
)
if CURRENT_TWEETS >= MAX_TWEETS:
return False
TWEETS.clear()
try:
TWEETS.append(
{
"text": repr(json.loads(data)["text"].strip()),
}
)
CURRENT_TWEETS += 1
TWEETS_BAR.update(CURRENT_TWEETS)
except Exception as e:
pass
return True
4. 数据抓取
然后我们设定关键字为virus。由于本次分析主要针对英语所以我们将语言为en就可以开始抓取了。过程应该会比较长,建议时不时瞄下进度条,有能力的可以加个邮件提醒啥的也是很棒棒的
from tweepy import Stream
worker = Monitor()
stream = Stream(AUTH,worker)
stream.filter(track=['virus','convid-19'],languages=['en'])
0x03 数据清洗
首先我们导入所需要的模块,并需要部分包需下载。
import nltk
nltk.download("words")
nltk.download("punkt")
nltk.download("wordnet")
nltk.download("stopwords")
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
from nltk.tokenize import word_tokenize
stopwords = set(stopwords.words("english"))
然后我们就需要进行清洗,就拿下图举个例子。
1.标准化(Normalization)
一般推文中会出现些许emoji表情,而这对此次的主题生成作用不大,于是我们定义方法将其过滤。
def clean_emoji(text):
return text.encode("ascii", "ignore").decode("ascii")
而后我们需要将所整条推文最小化并过滤掉,例如#topic 、@xxx、链接等等无用内容。
由于推文数量较大,我们通过re.compile提前生成规则以保证效率
import re
reg_map = {
re.compile("rt [@0-9a-z_]{0,10}:"),
re.compile("http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+"),
re.compile("#[0-9a-z]+"),
re.compile("@[0-9a-z]+"),
}
def lower_and_remove_with_reg(text: str) -> str:
text = text.lower()
for v in reg_map:
text = v.sub("", text)
return text
2. 分词(Tokenization&Stop words)
简单的解释就是把句子分成一个个的单词,类似text.split(),但我们有更合理的方式,顺带在分词后把停顿词及杂词删去
def tokenize_and_remove_stopwords(text: str) -> str:
for word in word_tokenize(text):
if word.isalnum() and word not in stopwords:
yield word
当然部分结果任然不是我们需要的,例如字母、空内容等
def word_check(word: str) -> bool:
if not word:
return
if word.__len__() < 2:
return
return True
3. 还原(Lemmatization)
单词中会一些变形,而这些对计算机来说不太友好,所以我们通过此方法例如将 better 变成 good。
def lemmatizing(word: str) -> str:
return WordNetLemmatizer().lemmatize(word, pos="v")
4. 推文处理方法
我们预设一个方法以组合上述几个方式处理每条推文。
def pre_proccess(line: str) -> list:
line = clean_emoji(line)
line = lower_and_remove_with_reg(line)
words = filter(word_check, tokenize_and_remove_stopwords(line))
words = map(lemmatizing, words)
return list(words)
5. 处理
然后我们开始预处理这3.5m条推文。为了节约内存,我们通过每10k条作为一个chunk的方式来读取。
READ_ROWS = 350*10000
CHUNK_SIZE = 10000
同时为了方便查看进度,我们设定一个ProccessBar来监控。
import math
PROCCESS_TIMES = math.floor(READ_ROWS / CHUNK_SIZE)
PRE_PROCCESS_BAR = progressbar.ProgressBar(max_value=PROCCESS_TIMES)
def work_and_update_bar(item, func, indexs):
result = item.apply(func)
PRE_PROCCESS_BAR.update(indexs + 1)
return result
并在最后合并(concat)所有Dataframe。
df = pd.concat(
(
work_and_update_bar(item["text"], pre_proccess, indexs)
for indexs, item in enumerate(
pd.read_csv(
str(tweets_file),
nrows=READ_ROWS,
chunksize=CHUNK_SIZE,
iterator=True,
names=["text", "geo"],
)
)
)
)
6. 概要查看
在处理完成后我们无聊得统计下词频,看看有些啥玩意儿。这里我们将使用chain将二维数组转成一位数组,并使用可视化技术更直观得展示。
%pip -q install stylecloud
import stylecloud
from itertools import chain
words = chain.from_iterable(df.to_list())
stylecloud.gen_stylecloud(' '.join(words),icon_name="fab fa-twitter")
然后结果如下,AMP是啥??
0x04 模型生成
最后我们开始生成模型,当然我们这里会使用较为快速的方法,不会太深究
首先我们生成词典过滤掉低频词并构建向量
import gensim
tweets_dicts = gensim.corpora.Dictionary(df)
tweets_dicts.filter_extremes(no_below=15)
corpus_result = [tweets_dicts.doc2bow(data) for data in df]
这里为了最大限度调用计算资源,我们使用LdaMulticore方法来生成模型(也不用期望会很快)。之后我们将打印20个相关的结果主题
lda_model = gensim.models.LdaMulticore(
corpus_result, num_topics=20, id2word=tweets_dicts, passes=2
)
for indexs, topic in lda_model.print_topics():
print(f"Topic: {indexs} Words: {topic}")
Topic: 0 Words: 0.048*"yes" + 0.046*"call" + 0.027*"trump" + 0.024*"amp" + 0.024*"name" + 0.018*"yet" + 0.013*"president" + 0.013*"omg" + 0.011*"haha" + 0.010*"say"
Topic: 1 Words: 0.045*"take" + 0.039*"great" + 0.037*"think" + 0.031*"better" + 0.030*"morning" + 0.029*"keep" + 0.020*"really" + 0.018*"end" + 0.015*"face" + 0.015*"lose"
Topic: 2 Words: 0.061*"watch" + 0.054*"shit" + 0.026*"week" + 0.024*"game" + 0.023*"next" + 0.020*"aint" + 0.019*"already" + 0.019*"year" + 0.018*"listen" + 0.018*"news"
Topic: 3 Words: 0.086*"one" + 0.085*"know" + 0.064*"thank" + 0.045*"lol" + 0.029*"never" + 0.029*"much" + 0.028*"cant" + 0.021*"mean" + 0.018*"sleep" + 0.015*"ill"
Topic: 4 Words: 0.090*"like" + 0.061*"look" + 0.040*"live" + 0.024*"always" + 0.022*"leave" + 0.022*"something" + 0.019*"wish" + 0.019*"drink" + 0.017*"house" + 0.015*"damn"
Topic: 5 Words: 0.039*"job" + 0.027*"ca" + 0.023*"true" + 0.022*"bless" + 0.022*"tonight" + 0.021*"lockdown" + 0.018*"link" + 0.018*"social" + 0.017*"open" + 0.015*"distance"
Topic: 6 Words: 0.118*"good" + 0.031*"ask" + 0.025*"beautiful" + 0.020*"song" + 0.019*"agree" + 0.017*"state" + 0.017*"team" + 0.017*"question" + 0.015*"full" + 0.013*"government"
Topic: 7 Words: 0.125*"im" + 0.104*"love" + 0.041*"miss" + 0.039*"say" + 0.038*"thats" + 0.026*"hear" + 0.018*"lmao" + 0.017*"sorry" + 0.017*"see" + 0.015*"nothing"
Topic: 8 Words: 0.030*"gt" + 0.028*"money" + 0.027*"help" + 0.019*"order" + 0.018*"school" + 0.017*"hell" + 0.016*"food" + 0.016*"tho" + 0.016*"free" + 0.015*"high"
Topic: 9 Words: 0.042*"world" + 0.030*"baby" + 0.028*"test" + 0.023*"movie" + 0.022*"close" + 0.021*"coronavirus" + 0.020*"case" + 0.018*"via" + 0.018*"pandemic" + 0.015*"least"
Topic: 10 Words: 0.054*"tell" + 0.036*"stop" + 0.031*"real" + 0.029*"do" + 0.027*"sunday" + 0.027*"girl" + 0.024*"virus" + 0.024*"everything" + 0.021*"must" + 0.020*"amaze"
Topic: 11 Words: 0.055*"want" + 0.048*"dont" + 0.042*"na" + 0.041*"right" + 0.030*"go" + 0.026*"life" + 0.023*"thing" + 0.022*"get" + 0.021*"yall" + 0.020*"play"
Topic: 12 Words: 0.065*"fuck" + 0.028*"sure" + 0.025*"send" + 0.024*"big" + 0.024*"eat" + 0.024*"make" + 0.020*"anyone" + 0.017*"kill" + 0.015*"music" + 0.014*"else"
Topic: 13 Words: 0.061*"would" + 0.043*"man" + 0.033*"god" + 0.020*"like" + 0.020*"run" + 0.019*"put" + 0.016*"point" + 0.016*"head" + 0.014*"turn" + 0.014*"ok"
Topic: 14 Words: 0.068*"back" + 0.049*"please" + 0.031*"post" + 0.029*"follow" + 0.025*"bitch" + 0.023*"video" + 0.021*"nice" + 0.019*"us" + 0.017*"forget" + 0.015*"photo"
Topic: 15 Words: 0.078*"day" + 0.031*"every" + 0.031*"night" + 0.025*"quarantine" + 0.024*"last" + 0.022*"hate" + 0.020*"die" + 0.019*"break" + 0.014*"heart" + 0.014*"believe"
Topic: 16 Words: 0.069*"work" + 0.053*"home" + 0.045*"stay" + 0.042*"new" + 0.039*"happy" + 0.033*"birthday" + 0.027*"everyone" + 0.022*"care" + 0.021*"safe" + 0.021*"check"
Topic: 17 Words: 0.029*"time" + 0.026*"youre" + 0.026*"wait" + 0.023*"ass" + 0.021*"lot" + 0.021*"tweet" + 0.019*"long" + 0.019*"get" + 0.018*"go" + 0.017*"bro"
Topic: 18 Words: 0.049*"feel" + 0.037*"way" + 0.037*"best" + 0.028*"find" + 0.026*"like" + 0.023*"years" + 0.023*"ever" + 0.021*"read" + 0.020*"little" + 0.020*"old"
Topic: 19 Words: 0.070*"get" + 0.053*"well" + 0.049*"let" + 0.035*"guy" + 0.035*"hope" + 0.033*"talk" + 0.025*"oh" + 0.019*"kid" + 0.018*"go" + 0.017*"come"
有人可能会问是否需要用到TFIDF,看看这里吧 Necessary to apply TF-IDF to new documents in gensim LDA model? - Stack Overflow
为了更好得观察模型,我们通过pyLDAvis生成了可视化图表。
!pip -q install pyLDAvis
import pyLDAvis.gensim
lda_display = pyLDAvis.gensim.prepare(
lda_model, corpus_result, tweets_dicts, sort_topics=True
)
pyLDAvis.display(lda_display)
下图是图表大致的样子,附带部分交互式按钮。
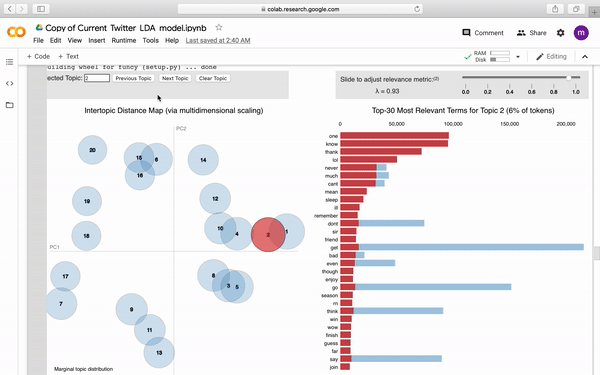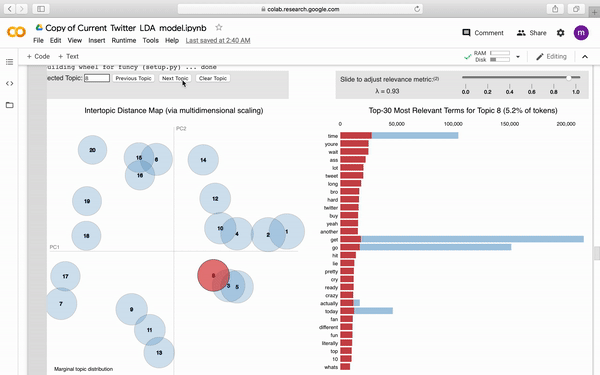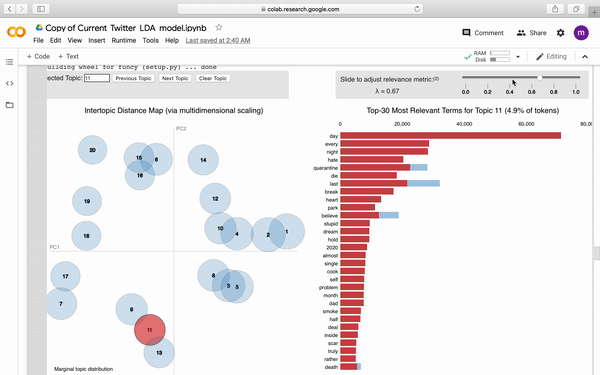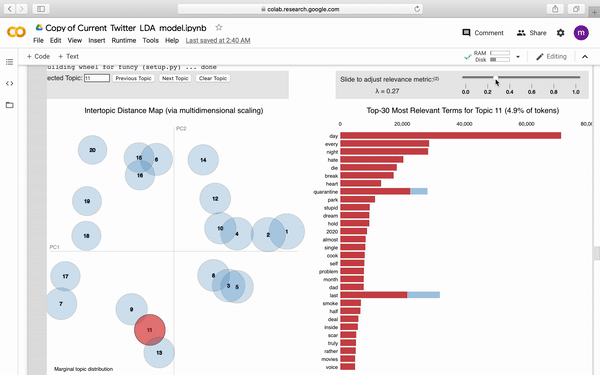
当然也别忘记了保存Model,毕竟这处理过程,时间也不短吧。借助强大的pathlib我们直接按照如下写法将其保存至GoogleDrive
lda_model_file = datasets_path / f'Stream_tweets_lda_model'
lda_model.save(str(lda_model_file))
最后的话,用墙外人民的话来总结就是:Gods bless humanity
